As we talk to the organizations that use OpenSanctions, the more we learn about the multitude of ways in which people use our data and service as building blocks in their own solutions: investigative tools, know-your-customer (KYC) workflows or even building complex knowledge graphs.

One such building block is yente, the OpenSanctions API service. While the API provides all the data you see when browsing and searching the OpenSanctions website, it's core function is entity matching: given a list of details about persons or companies, such as customers or investigation targets, the tool will score each against the OpenSanctions database and flag the ones likely to be sanctioned or politically exposed.
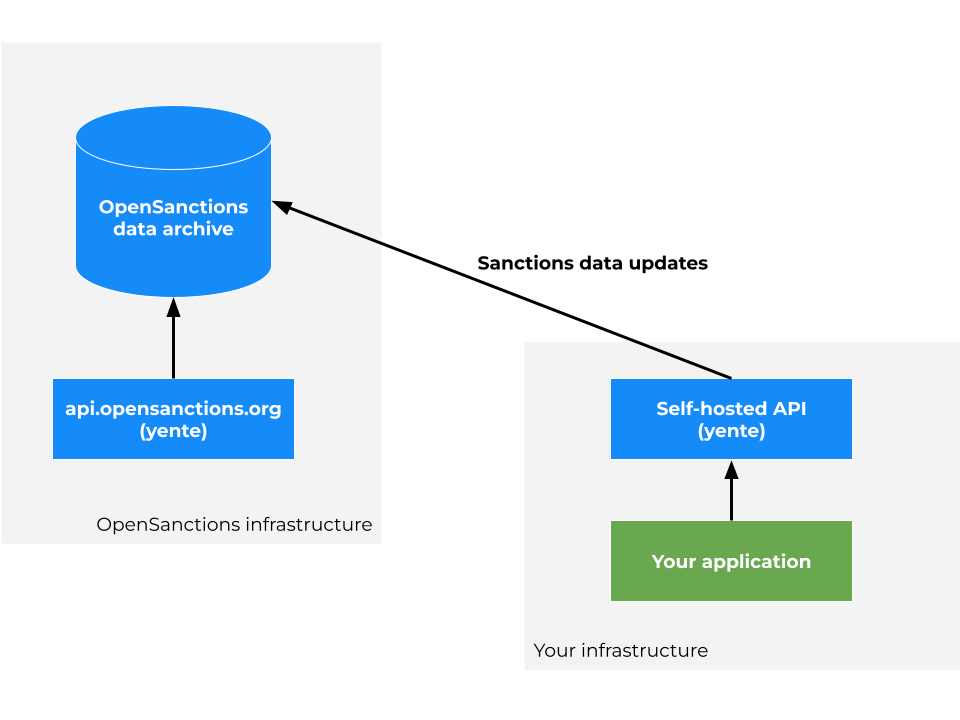
What sets yente apart from similar matching APIs is that it is fully open-source. This means that you can not only download the software and run it inside of your own infrastructure, and you can even change and extend it to perfectly fit your business needs.
Imagine, for example, that you worked in a regulated industry and are building a KYC workflow. Doing so may require you to adopt specific matching rules, or to screen for a local dataset of high-risk entities that is not included in OpenSanctions. Or, you may wish to screen entities against a completely different dataset (like the ICIJ Offshore Leaks database).
Bring your own data
yente makes all this very easy: adding a custom list - perhaps a list of entities that you have previously investigated or flagged, or a whole extra dataset - is simple. All you need to do is convert your data to the FollowTheMoney data format used by OpenSanctions, and tell the API server where it can find it.
To get you started, we're already working to build up a growing number of free-to-use FollowTheMoney datasets, for example the ICIJ OffshoreLeaks database, or the Global Legal Entity Identifier (LEI) reference data shared by GLEIF. More on that soon.
Of course, open source code also means functional customization: you only want to match entities using their primary names, but ignore alias names? No problem. Train a matching engine against the decisions made by your in-house analysts? Easy, let’s go.
Keeping it private
What's even better: self-hosting the API means your own data remains within your infrastructure. Instead of sending data about your customers or investigation targets to a hosted service outside of your control, the OpenSanctions bulk data will be downloaded from our servers into your systems. All matching will take place there.
If you're thinking: why doesn't everybody do this? The answer is simple: because it requires bulk data access.
Traditional due diligence data vendors treat their datasets as a secret crown jewel, only to be shared with their most trusted partners, open bulk data is the default for OpenSanctions. It's by working with the data openly and transparently that we create the freedom for you to build more tailored solutions, but also to better protect your in-house data.
